Bezouts Identity
Introduction
In this series of articles on number theory, today we talk about the Bézout’s Identity.
Let a and b be integers with greatest common divisor d. Then there exist integers x and y such that ax + by = d. The integers of the form az + bt are exactly the multiples of d.
The integers x and y are called Bézout coefficients for (a, b); they are not unique
Euclidean Algorithm To Compute GCD
This is a long-form post about the Euclidean algorithm to compute the greatest common divisors of two integers. The article starts from the fundamentals and explains why it works better than the naive algorithm. The author also explains the computational complexity and the mathematics of the algorithm.
Prereseqisites
- Fundamental arithmetic and an understanding of the greatest common divisor(GCD).
- Introductory concepts in algebra and logarithms, including mathematical induction.
- Overview of modular arithmetic.
- Familiarity with the Fibonacci series. An excellent video tutorial of the Fibonacci series on Youtube.
- An introduction to the big O notation.
- Basics Python programming skills.
- Curiosity.
- Patience to read long articles. It is okay to read it in more than one sitting. Taking notes will be benefitial for the learner. Re-reading the article a few times is encouraged.
Introduction
What Is GCD?
GCD, the greatest common divisor is the largest number that divides the given two integers.
Breaking Into IT
The Traditional Way Of Learning
In the olden days, you had to go to school or college to educate yourself. In the classroom, listen to the lectures, make notes and enjoy some discussions with the lecturer and classmates. At home, you would refer to textbooks and complete the work suggested in the curriculum.
Other than college, you had and have the option of private tuition. There are many brick and mortar training academies that supplement the colleges and universities.
Data Structures And Algorithms
Data Structures And Algorithms
- Data Structures: A data structure is a technique of storing data in a computer so that it can be accessed and modified efficiently.
- Algorithms: An algorithm is a step-by-step instruction to perform a task.
Why Should I Learn Data Structures And Algorithms?
- Enhance your problem solving skills.
- Write efficient code that is performant and scalable.
- Specialized fields: machine learning, data science, artificial intelligence and other engineering fields deal with complex data and require efficient processing. To delve into such fascinating fields of engineering, having a firm grounding in data structures and algorithms is beneficial and in many cases required.
Can I Develop Applications Without Studying Data Structures And Algorithms?
Yes, sure. A lot of applications just store some data in a datastore, typically a relational database and have some procedures to show this data in a user interface, most commonly the web browser. The crux of such applications can be defined using the acronym CRUD. CRUD stands for Create, Read, Update and Delete. Often you are doing one of these CRUD functions in the context of persistent storage of your application:
AI
Introduction
This is an anchor post about machine learning and artificial intelligence.
Observations On AI
Revolution in Text Generation: Generative AI is making significant strides in text production, promising a surge in the quality and quantity of text-based content. This encompasses everything from blog posts and articles to comprehensive reference books, transforming how information is created and disseminated.
Advancements In AI-Generated Imagery: The evolving capabilities of AI in image generation are noteworthy. These advancements are set to enrich various fields with innovative and creative visual content, offering new dimensions in digital art, marketing, and visual storytelling.
Kubernetes RBAC Objects For Cluster Administration
In a previous series of blog posts, we discussed the Kubernetes objects typically used to run a web application. We covered, Namespace, Pod, ConfigMap, Secret, Service, Deployment, ServiceAccount, Ingress, PDB, HPA, PV, PVC, Job and CronJob.
In this post, we will discuss some fundamental building blocks for the Kubernetes cluster administration: RBAC objects.
In most situations, Kubernetes API server is started with the flag --authorization-mode=RBAC which enables RBAC in
the cluster.
Automating Virtual Machine Installation Using libvirt, virsh And cloud-init
Introduction

We have the host machine with the OS Ubuntu 22.04. On this PC or server, we will create two virtual machine guests:
myubuntu2204test01having static IP of192.168.122.146myubuntu2204test02having static IP of192.168.122.147
The guest VMs will use the default network created by libvirt. The gateway IP for the default network
is 192.168.122.1.
We will achieve automation using libvirt, qemu and cloud-init. To go through the article and exercise,
you should have a rudimentary understanding of Linux system administration and networking.
Writing A Kubernetes Controller: Part I
This is a guide to write a Kubernetes controller. We will kick off by inspecting the Kubernetes API from inside a pod within the cluster. Minikube suffices for this exercise. But you can conduct the exercise to any Kubernetes cluster.
The controller watches events related to Kubernetes pods using the Kubernetes API. When there is a new event, the controller logs the event’s type and the name of the affected pod. This controller can be extended to perform other actions when pod events occur, such as scaling the number of replicas for a deployment, sending notifications, or triggering a custom script or program.
Loading SSH Key Into Memory
So, you have an SSH key pair. The public key has been added on to the server. On the client, ie your laptop/desktop you have your private key. For some reason, your private key has not been loaded into memory.
All you have to do is start the ssh-agent and then load the key into memory via ssh-add.
Step 1: Start the agent
eval $(ssh-agent)
Step 2: load the key into memory
Linux KVM Bridge
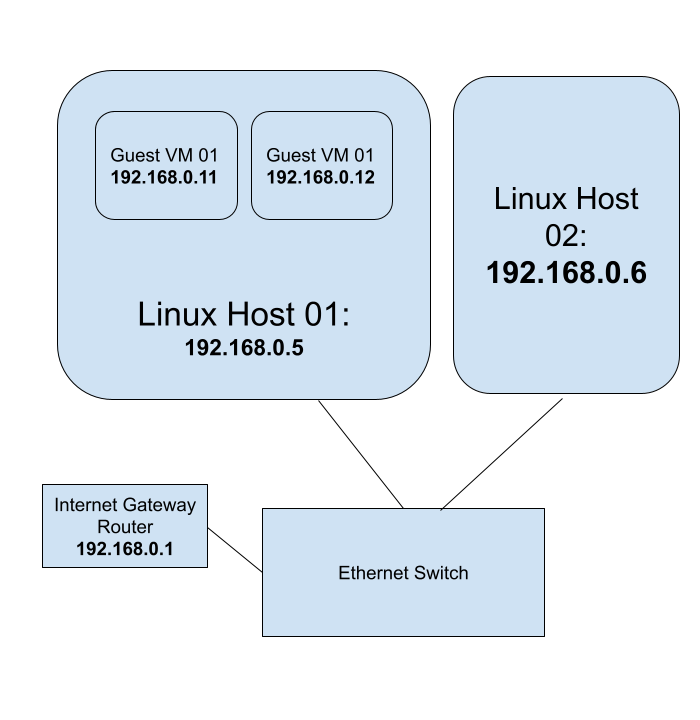
Using Linux KVM, Expose Virtual Guests On The LAN
Audience: The blog post is for beginner to intermediary Linux system administrators.
- You should have a thorough understanding of the shell commands and
- be comfortable on the command line
- be able to install and configure packages, etc.
- be able to start and stop services using
systemd - be familiar with Linux configuration files
- be able to set Linux kernel parameters using
sysctl - be able to enable and disable Kernel modules
- be comfortable installing and using guest VMs using
libvirt
You should have a rudimentary understanding of networking concepts and tooling such as